 DAUX Blueprint
DAUX Blueprint
Abstract
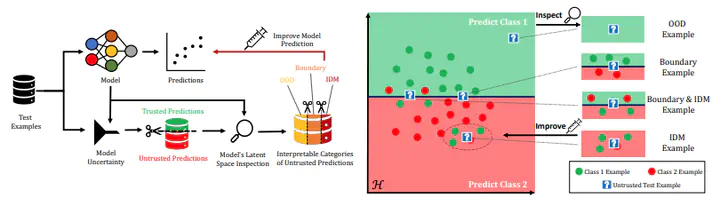
Uncertainty quantification (UQ) is essential for creating trustworthy machine learning models. Recent years have seen a steep rise in UQ methods that can flag suspicious examples, however, it is often unclear what exactly these methods identify. In this work, we propose a framework for categorizing uncertain examples flagged by UQ methods. We introduce the confusion density matrix—a kernel-based approximation of the misclassification density—and use this to categorize suspicious examples identified by a given uncertainty method into three classes: out-of-distribution (OOD) examples, boundary (Bnd) examples, and examples in regions of high in-distribution misclassification (IDM). Through extensive experiments, we show that our framework provides a new and distinct perspective for assessing differences between uncertainty quantification methods, thereby forming a valuable assessment benchmark.
Jonathan Crabbé
PhD Researcher
My research focuses on explainable artificial intelligence, representation learning and robust machine learning.