Robust multimodal models have outlier features and encode more concepts
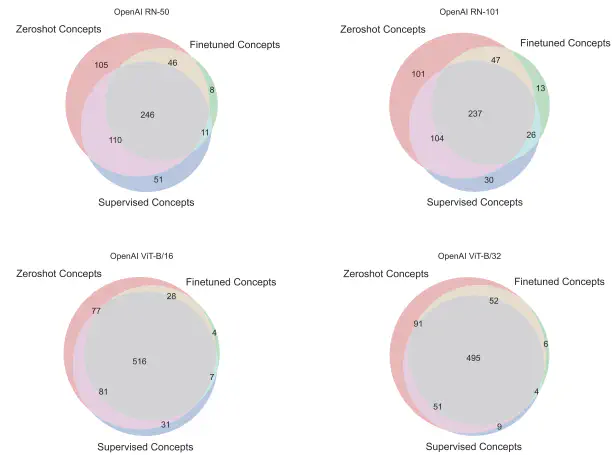 Overlap between concepts learned by different models
Overlap between concepts learned by different models
Abstract
What distinguishes robust models from non-robust ones? This question has gained traction with the appearance of large-scale multimodal models, such as CLIP. These models have demonstrated unprecedented robustness with respect to natural distribution shifts. While it has been shown that such differences in robustness can be traced back to differences in training data, so far it is not known what that translates to in terms of what the model has learned. In this work, we bridge this gap by probing the representation spaces of 12 robust multimodal models with various backbones (ResNets and ViTs) and pretraining sets (OpenAI, LAION-400M, LAION-2B, YFCC15M, CC12M and DataComp). We find two signatures of robustness in the representation spaces of these models (1) Robust models exhibit outlier features characterized by their activations, with some being several orders of magnitude above average. These outlier features induce privileged directions in the model representation space. We demonstrate that these privileged directions explain most of the predictive power of the model by pruning up to 80% of the least important representation space directions without negative impacts on model accuracy and robustness; (2) Robust models encode substantially more concepts in their representation space. While this superposition of concepts allows robust models to store much information, it also results in highly polysemantic features, which makes their interpretation challenging. We discuss how these insights pave the way for future research in various fields, such as model pruning and mechanistic interpretability.
Jonathan Crabbé
PhD Researcher
My research focuses on explainable artificial intelligence, representation learning and robust machine learning.