Benchmarking Heterogeneous Treatment Effect Models through the Lens of Interpretability
 Benchmark Blueprint
Benchmark Blueprint
Abstract
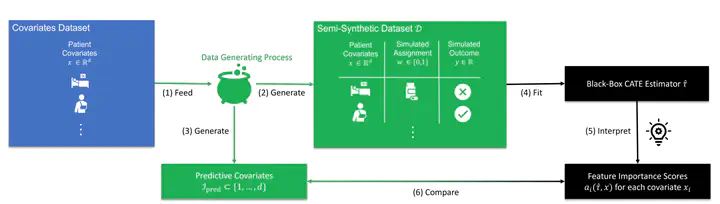
Estimating personalized effects of treatments is a complex, yet pervasive problem. To tackle it, recent developments in the machine learning (ML) literature on heterogeneous treatment effect estimation gave rise to many sophisticated, but opaque, tools. Due to their flexibility, modularity and ability to learn constrained representations, neural networks in particular have become central to this literature. Unfortunately, the assets of such black boxes come at a cost, models typically involve countless nontrivial operations, making it difficult to understand what they have learned. Yet, understanding these models can be crucial – in a medical context, for example, discovered knowledge on treatment effect heterogeneity could inform treatment prescription in clinical practice. In this work, we therefore use post-hoc feature importance methods to identify features that influence the model predictions. This allows us to evaluate treatment effect estimators along a new and important dimension that has been overlooked in previous work. We construct a benchmarking environment to empirically investigate the ability of personalized treatment effect models to identify predictive covariates – covariates that determine differential responses to treatment. Our benchmarking environment then enables us to provide new insight into the strengths and weaknesses of different types of treatment effects models as we modulate different challenges specific to treatment effect estimation – e.g. the ratio of prognostic to predictive information, the possible nonlinearity of potential outcomes and the presence and type of confounding.
Jonathan Crabbé
PhD Researcher
My research focuses on explainable artificial intelligence, representation learning and robust machine learning.