 Learners Collusion
Learners Collusion
Abstract
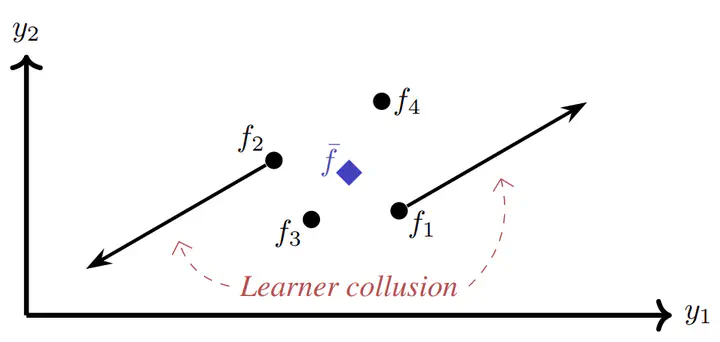
Ensembles of machine learning models have been well established as a powerful method of improving performance over a single model. Traditionally, ensembling algorithms train their base learners independently or sequentially with the goal of optimizing their joint performance. In the case of deep ensembles of neural networks, we are provided with the opportunity to directly optimize the true objective: the joint performance of the ensemble as a whole. Surprisingly, however, directly minimizing the loss of the ensemble appears to rarely be applied in practice. Instead, most previous research trains individual models independently with ensembling performed post hoc. In this work, we show that this is for good reason - joint optimization of ensemble loss results in degenerate behavior. We approach this problem by decomposing the ensemble objective into the strength of the base learners and the diversity between them. We discover that joint optimization results in a phenomenon in which base learners collude to artificially inflate their apparent diversity. This pseudo-diversity fails to generalize beyond the training data, causing a larger generalization gap. We proceed to demonstrate the practical implications of this effect finding that, in some cases, a balance between independent training and joint optimization can improve performance over the former while avoiding the degeneracies of the latter.
Jonathan Crabbé
PhD Researcher
My research focuses on explainable artificial intelligence, representation learning and robust machine learning.