Evaluating the Robustness of Interpretability Methods through Explanation Invariance and Equivariance
 Non-Robust Explanations
Non-Robust Explanations
Abstract
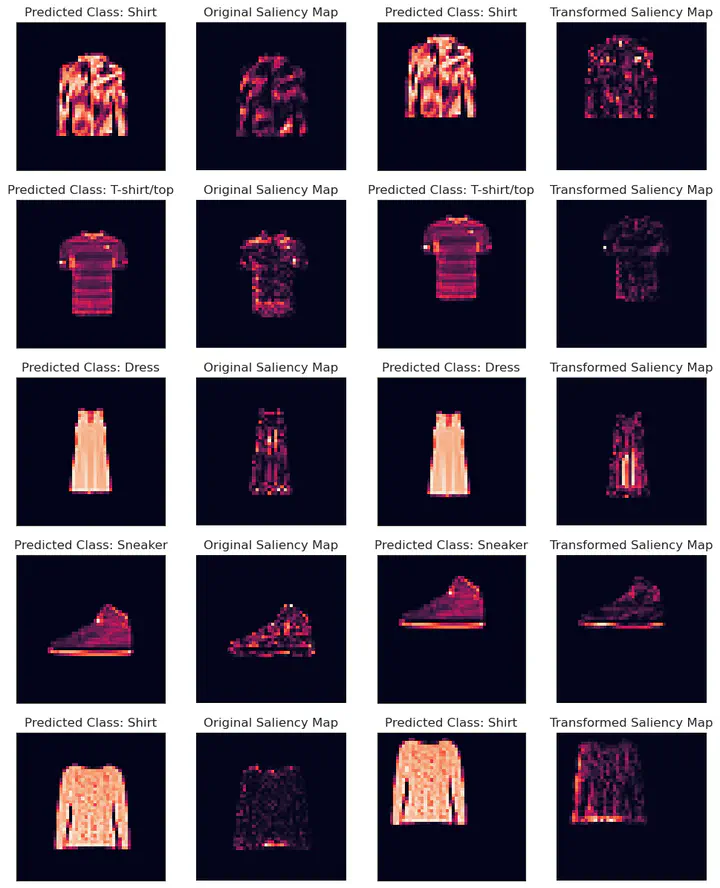
Interpretability methods are valuable only if their explanations faithfully describe the explained model. In this work, we consider neural networks whose predictions are invariant under a specific symmetry group. This includes popular architectures, ranging from convolutional to graph neural networks. Any explanation that faithfully explains this type of model needs to be in agreement with this invariance property. We formalize this intuition through the notion of explanation invariance and equivariance by leveraging the formalism from geometric deep learning. Through this rigorous formalism, we derive (1) two metrics to measure the robustness of any interpretability method with respect to the model symmetry group; (2) theoretical robustness guarantees for some popular interpretability methods and (3) a systematic approach to increase the invariance of any interpretability method with respect to a symmetry group. By empirically measuring our metrics for explanations of models associated with various modalities and symmetry groups, we derive a set of 5 guidelines to allow users and developers of interpretability methods to produce robust explanations.
Jonathan Crabbé
PhD Researcher
My research focuses on explainable artificial intelligence, representation learning and robust machine learning.