Jonathan Crabbé
Jonathan Crabbé
Home
Posts
Projects
Talks
Publications
Contact
CV
Light
Dark
Automatic
Deep learning
Robust multimodal models have outlier features and encode more concepts
We investigate what makes multimodal models that show good robustness with respect to natural distribution shifts (e.g., zero-shot CLIP) different from models with lower robustness using interpretability.
Jonathan Crabbé
,
Pau Rodríguez
,
Vaishaal Shankar
,
Luca Zappella
,
Arno Blaas
PDF
Cite
Project
Project
Project
Explaining the Absorption Features of Deep Learning Hyperspectral Classification Models
Over the past decade, Deep Learning (DL) models have proven to be efficient at classifying remotely sensed Earth Observation (EO) …
Arthur Vandenhoeke
,
Lennert Antson
,
Guillem Ballesteros
,
Jonathan Crabbé
,
Michal Shimoni
PDF
Cite
Project
Evaluating the Robustness of Interpretability Methods through Explanation Invariance and Equivariance
We assess the robustness of various interpretability methods by measuring how their explanations change when applying symmetries of the model to the input features.
Jonathan Crabbé
,
Mihaela van der Schaar
PDF
Cite
Code
Project
Project
Poster
TANGOS: Regularizing Tabular Neural Networks through Gradient Orthogonalization and Specialization
We introduce TANGOS, a regularization method that orthogonalizes the gradient attribution of neurons to improve the generalization of deep neural networks on tabular data.
Alan Jeffares
,
Tennison Liu
,
Jonathan Crabbé
,
Fergus Imrie
,
Mihaela van der Schaar
PDF
Cite
Code
Project
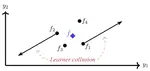
Joint Training of Deep Ensembles Fails Due to Learner Collusion
Training deep ensembles via a shared objective results in degenerate behavior.
Alan Jeffares
,
Tennison Liu
,
Jonathan Crabbé
,
Mihaela van der Schaar
PDF
Cite
Project
Project
Poster
Concept Activation Regions: A Generalized Framework For Concept-Based Explanations
We extend existing feature and example importance methods to unsupervised learning.
Jonathan Crabbé
,
Mihaela van der Schaar
PDF
Cite
Code
Project
Project
Video
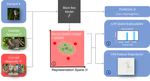
Label-Free Explainability for Unsupervised Models
We extend existing feature and example importance methods to unsupervised learning.
Jonathan Crabbé
,
Mihaela van der Schaar
PDF
Cite
Code
Project
Project
Video
Representation Learning
Learning realistic representations of the world.
Robust Machine Learning
Making sure that machines are doing what they are supposed to do.
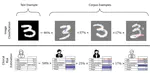
Explaining Latent Representations with a Corpus of Examples
We introduce SimplEx, a case-based reasoning explanation method that permits to decompose latent representations with a corpus of example.
Jonathan Crabbé
,
Zhaozhi Qian
,
Fergus Imrie
,
Mihaela van der Schaar
PDF
Cite
Code
Project
Video
»
Cite
×