Interpretable Machine Learning
 Photo by sdecoret on Shutterstock
Photo by sdecoret on Shutterstock
How can we make a machine learning model convincing? If accuracy is undoubtedly necessary, it is rarely sufficient. Models such as neural networks typically involve millions of operations to turn their input data into a prediction. This complexity permits to accurately solve hard problems like computer vision and protein structure prediction. However, this accuracy comes at the expense of interpretability: these complex models appear as black boxes for human users. When models penetrate critical areas such as medicine, finance and the criminal justice system, their black-box nature appears as a major issue. An important question follows: is it possible to explain the predictions of complex machine-learning models?
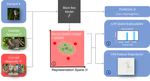
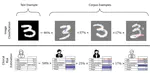
Explainable AI tackles this question by providing an interface between complex models and human users. To illustrate, let us consider the example of a medical machine learning model that recommends a treatment for a patient. By using post-hoc explainability, we can answer crucial questions such as “What part of this patient’s data motivates the model’s recommendation?” or “Are there similar patients previously seen by the model for which this treatment worked?”. In a setting where human knowledge is available (e.g. computer vision), this type of information is crucial to validate/debug the model. In a setting where little human knowledge (e.g. scientific discovery), this type of information permits to extract knowledge from the model.
Jonathan Crabbé
PhD Researcher
My research focuses on explainable artificial intelligence, representation learning and robust machine learning.