Jonathan Crabbé
Jonathan Crabbé
Home
Posts
Projects
Talks
Publications
Contact
CV
Light
Dark
Automatic
Explainability
Robust multimodal models have outlier features and encode more concepts
We investigate what makes multimodal models that show good robustness with respect to natural distribution shifts (e.g., zero-shot CLIP) different from models with lower robustness using interpretability.
Jonathan Crabbé
,
Pau Rodríguez
,
Vaishaal Shankar
,
Luca Zappella
,
Arno Blaas
PDF
Cite
Project
Project
Project
Explaining the Absorption Features of Deep Learning Hyperspectral Classification Models
Over the past decade, Deep Learning (DL) models have proven to be efficient at classifying remotely sensed Earth Observation (EO) …
Arthur Vandenhoeke
,
Lennert Antson
,
Guillem Ballesteros
,
Jonathan Crabbé
,
Michal Shimoni
PDF
Cite
Project
Evaluating the Robustness of Interpretability Methods through Explanation Invariance and Equivariance
We assess the robustness of various interpretability methods by measuring how their explanations change when applying symmetries of the model to the input features.
Jonathan Crabbé
,
Mihaela van der Schaar
PDF
Cite
Code
Project
Project
Poster
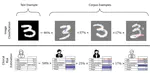
Concept Activation Regions: A Generalized Framework For Concept-Based Explanations
We extend existing feature and example importance methods to unsupervised learning.
Jonathan Crabbé
,
Mihaela van der Schaar
PDF
Cite
Code
Project
Project
Video
Benchmarking Heterogeneous Treatment Effect Models through the Lens of Interpretability
We benchmark treatment effect models with interpretability tools.
Jonathan Crabbé
,
Alicia Curth
,
Ioana Bica
,
Mihaela van der Schaar
PDF
Cite
Code
Project
Project
Label-Free Explainability for Unsupervised Models
We extend existing feature and example importance methods to unsupervised learning.
Jonathan Crabbé
,
Mihaela van der Schaar
PDF
Cite
Code
Project
Project
Video
Latent Density Models for Uncertainty Categorization
We introduce DAUX, an interpretability framework to interpret model uncertainty.
Hao Sun
,
Boris van Breugel
,
Jonathan Crabbé
,
Nabeel Seedat
,
Mihaela van der Schaar
PDF
Cite
Project
Project
Poster
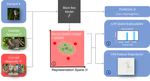
Explaining Latent Representations with a Corpus of Examples
We introduce SimplEx, a case-based reasoning explanation method that permits to decompose latent representations with a corpus of example.
Jonathan Crabbé
,
Zhaozhi Qian
,
Fergus Imrie
,
Mihaela van der Schaar
PDF
Cite
Code
Project
Video
Explaining Time Series Predictions with Dynamic Masks
We introduce Dynamask, a perturbation-based feature importance method to explain the predictions of time series models.
Jonathan Crabbé
,
Mihaela van der Schaar
PDF
Cite
Code
Project
Video
Interpretable Machine Learning
Creating an interface between machine learning models and human beings.
Cite
×